Obtaining latest PK value Windows vs Joins with spark


When working with change data capture data, containing sometimes just the updated cells for a given PK, it is not easy to efficiently obtain the latest value for the entry (row). Let's dive into an example. First though, we need a couple of definitions about change data capture (CDC):
Change data capture records insert, update, and delete activity that is applied to a SQL Server table. This makes the details of the changes available in an easily consumed relational format. Column information and the metadata that is required to apply the changes to a target environment is captured for the modified rows and stored in change tables that mirror the column structure of the tracked source tables. Table-valued functions are provided to allow systematic access to the change data by consumers.
Microsoft SQL server docs
In databases, change data capture (CDC) is a set of software design patterns used to determine (and track) the data that has changed so that action can be taken using the changed data. CDC is also an approach to data integration that is based on the identification, capture and delivery of the changes made to enterprise data sources.
CDC solutions occur most often in data-warehouse environments since capturing and preserving the state of data across time is one of the core functions of a data warehouse, but CDC can be utilized in any database or data repository system.
Change Data Capture - Wikipedia
Let's say we have the following data in our table. It will need a primary key (one or more columns) and a column to indicate the latest version. This could be a timestamp for example. The important thing is that we have the restriction UNIQUE(pk, versionCol)
| pk | time | name | address | phone_number |
|---|---|---|---|---|
| 1 | 1 | Jane Doe | 666343 | |
| 2 | 2 | Jack | 23 Street | 2323332 |
And now let's say we receive some updates at a later point in time.
| pk | time | name | address | phone_number |
|---|---|---|---|---|
| 3 | 3 | Charles | ||
| 1 | 4 | Jane Doe | 4 Plaza | 666343 |
| 3 | 5 | Charles | 4 Plaza | 634342 |
As you can see, we get the entire row with the update.
The current (materialized) view on the data will be the following:
| pk | time | name | address | phone_number |
|---|---|---|---|---|
| 1 | 4 | Jane Doe | 4 Plaza | 666343 |
| 2 | 2 | Jack | 23 Street | 2323332 |
| 3 | 5 | Charles | 4 Plaza | 634342 |
Let's now see how we can do this in Spark, the main big data processing engine.
Spark UI
When developing and maintaining Spark applications, your main friend is the UI there you can visually see what spark does under the hood, and grasp what can you change in order to optimize your code. If you run spark in local mode, it is usually located in http://localhost:4040
For more information, take a look at the following video.
We will explore two different ways of materializing the tables in spark, and explore them via the UI.
Joins
One of the things you first see when leaning SQL, but very difficult to master: the join. In this, we are building a table containing the max time value for every pk and doing an INNER JOIN to get only the ones that have the max value.
val maxUpdate = account.select("pk", "time").
groupBy("pk").agg(max("time").as("time"))
val latestValuesJ = account.join(maxUpdate, Seq("pk", "time"))
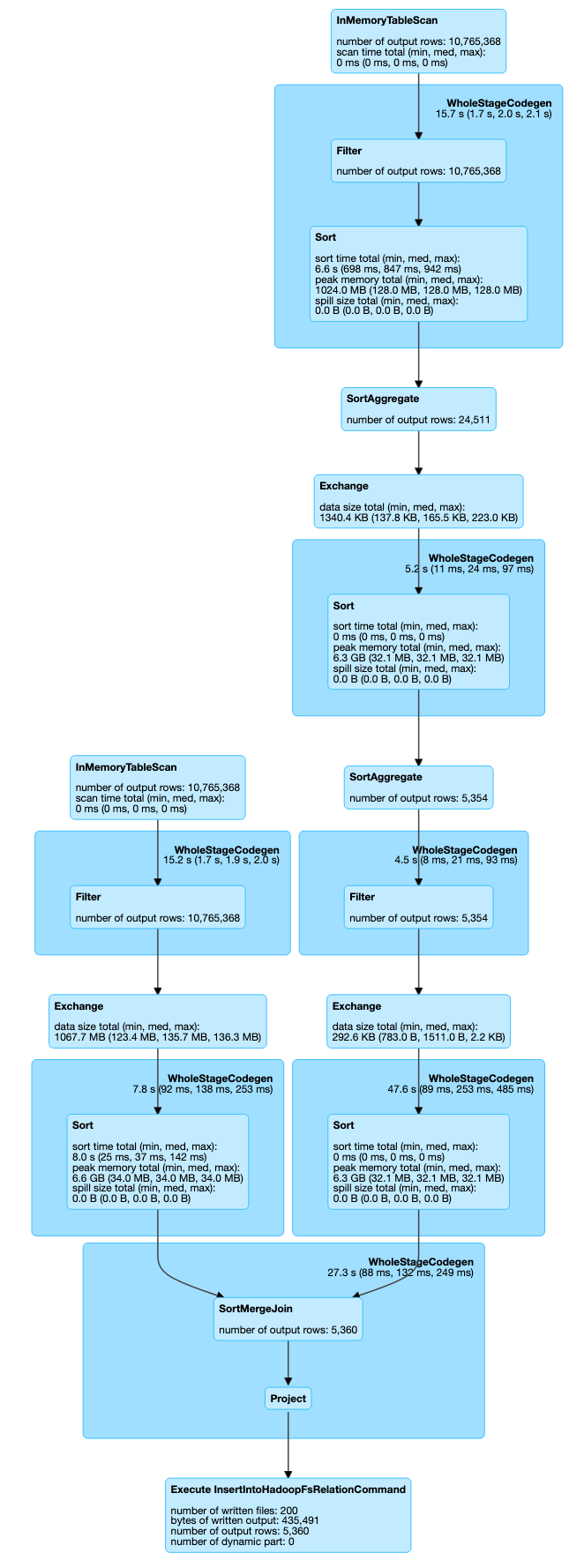
We can see in the SQL diagram that we get a complex plan. We have several stages with a couple of shuffles. If you have a little of experience using spark, you know that shuffles are not good and should be avoided.
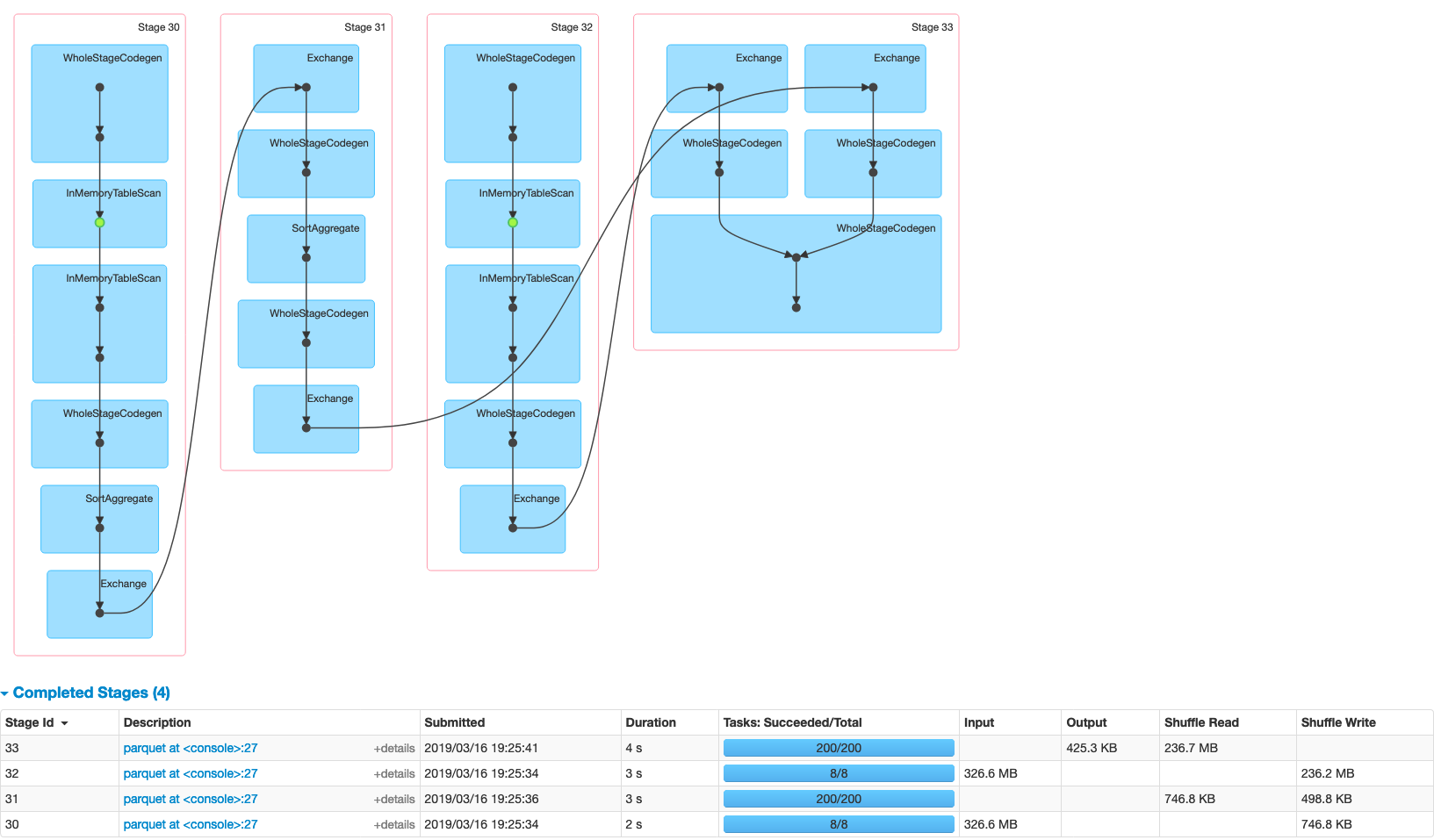
In the job tab, we can confirm that we have 4 stages for the job, and we get the total time: 12 seconds.
Using windows
A less well known feature of spark and SQL is the windowing function. It is designed to efficiently process workloads that usually do group by and aggregations. Usually found when working with time series, as we are doing now.
import org.apache.spark.sql.expressions.Window
val latestSpec = Window.partitionBy("pk").orderBy(col("time").desc)
val latestValues = account.withColumn("max_time", first("time").
over(latestSpec)).filter("time==max_time").drop("max_time")
Instead of doing a join we add a column with the max time, and then filtering-out the rows that do not comply with the condition set.
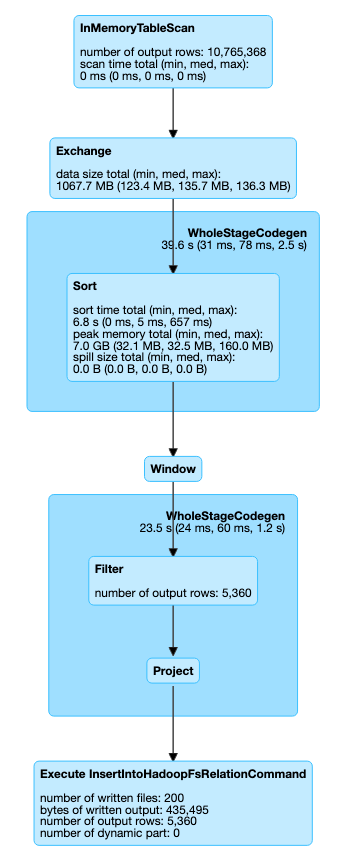
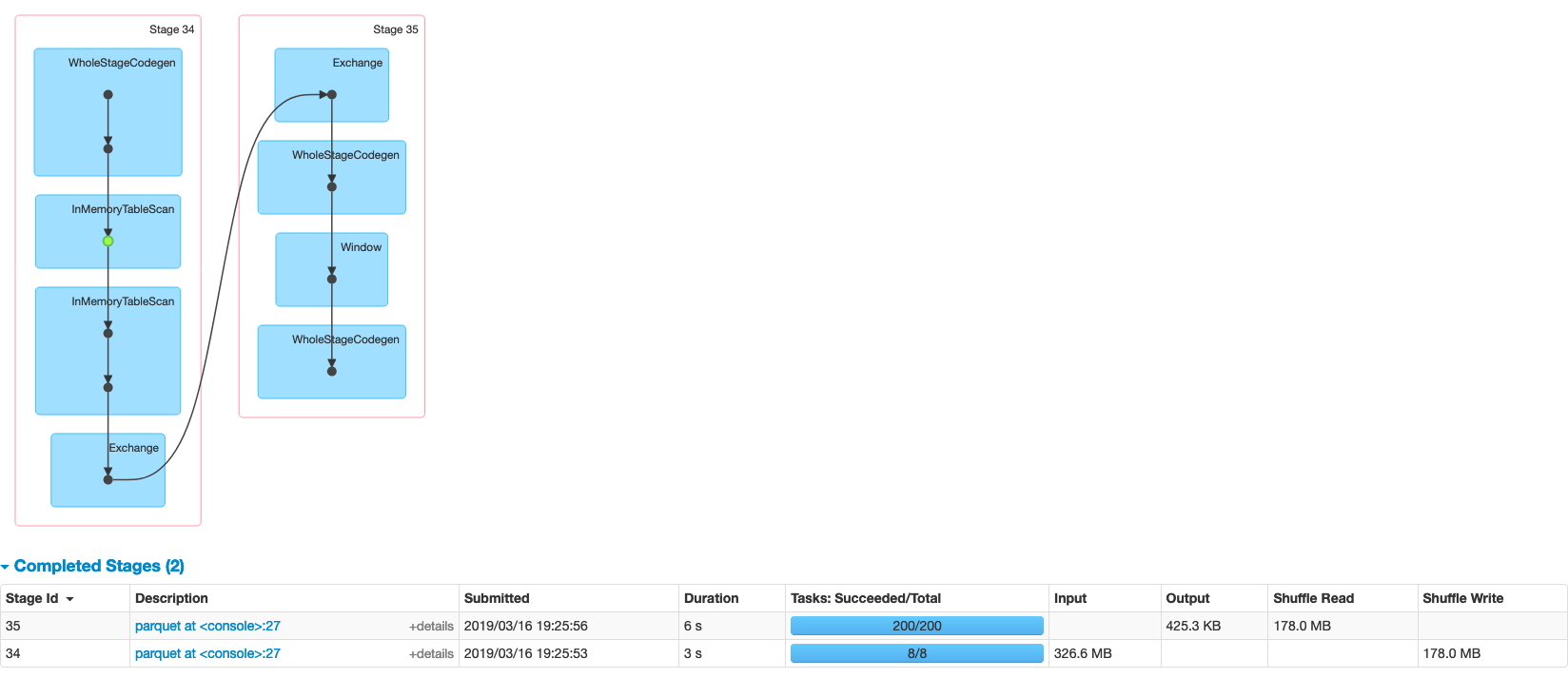
We can see the SQL diagram is much nicer, and we can confirm this by looking into the job tab, where we have only two stages and reducing the computing time to 9 seconds instead of 12. A 33.3% improvement.
Learn more:


![Leptos: rust full stack [Code + Slides + Video]](/content/images/size/w600/2025/12/leptos-talk.png)
