Data Concept: Idempotence
Idempotentity is not only useful in the design of data pipelines, but also as a system-wide concern, since if one step is not idempotent, the entire quality of the results will be affected. Let's look at a practical example.

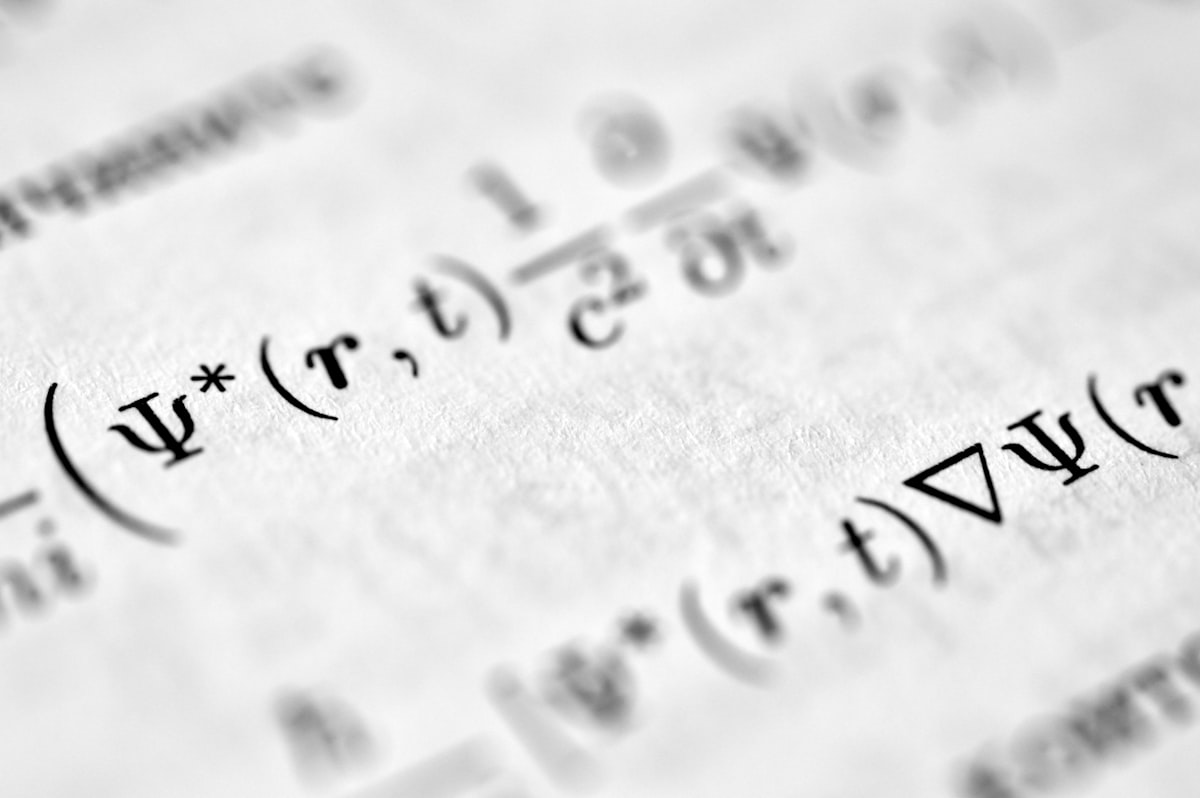
Of all the knowledge about data systems that I share with my master's students, there is one principle that, when they grasp it, helps them understand how and why things are done: idempotence. It gives them an understanding of the whole data process, from low to high-level.
At its core, idempotence means you can perform an operation, like an ETL task, repeatedly and still get the same outcome each time. Picture extracting yesterday's sales and storing them in our Data Lake – no matter how many times we run the process, we end up with the same result.
A quick example with python:
# Operation 1
counter = 0
# Operation 2
counter = counter + 1
Executing Operation 1 multiple times keeps counter at 0. But with Operation 2, each execution increments counter, making it non-idempotent.
While in a simple program this will not be an issue, since the OS and language guarantees that it will only execute this operation once, distributed data systems introduce complexities and this might not be the case, and we must work our way arround this fact. We must ensure our operations avoid duplications and inaccuracies.
Anoter challenge we face is that now, not only the individual operations have to be idempotent, but also the entire workflow. From data extraction to the report/dashboard. An error in any step could lead to erroneous end results, like a flawed sales report.
Practical scenario
Let's follow typical real world example: we are extracting two tables (sales and customers) from the operational database. We'll need to join both and do some analytics like the number of sales per month and city of customer.
flowchart TB
customers --> customers_raw[customers]
sales --> sales_raw[sales]
subgraph source[Operational DB]
sales ~~~ customers
end
subgraph data_pltf[Data Platform]
sales_raw ~~~ customers_raw
customers_raw --> statistics
sales_raw --> statistics
end
data_pltf ~~~ source
The simplest solution for an idempotent workflow is extracting both tables, doing the computation and overwriting the results every time. We call this type of workflow: full
However, what if we can't extract all the data for sales every time? (e.g. the table is too big) Let's say we just download yesterday's sales ( ~incremental ). A couple of questions arise:
- How to we update the monthly statistics? Do we overwrite each month? Do we just add the new numbers?
- If the pipeline failed a couple of days, how do we re-compute 2-3 days worth of data? (When the pipeline only processes yesterday's data)
- What happens if an order from last month was deleted/canceled? We shall not compute it towards the sales. Do we re-compute all the statistics?
While there are several strategies to address those topics, all of them require some sort of coordination across the different steps. An added complexity that must be tackled thinking about re-executions, data correctness and data update processes.
So you see that just introducing how the data is updated (full vs incremental), we are facing several challenges where idempotency plays a role in its solution.
Given the dire repercussions of bad reporting, it's clear that we must prioritize idempotence as a workflow and system-wide concern, not something to be solved with a single tool or quick fix.
Only you can define what "good data" means for your application, and idempotence is the cornerstone that ensures you achieve it consistently.


![Leptos: rust full stack [Code + Slides + Video]](/content/images/size/w600/2025/12/leptos-talk.png)
