Finding latest non-null values in columns


Imagine we have a table with a sort of primary key where information is added or updated partially: not all the columns for a key are updated each time, but we now want to have a consolidated view of the information, with just one value of the key containing the most up-to-date information. Let's see an example of what I mean:
| id | time | val1 | val2 |
|---|---|---|---|
| 1 | 1 | dataa | dataOld |
| 1 | 2 | updateddata |
We can see here that the update is only done to one column, setting a null value on the other one. This situation is not easy to solve in SQL, involving inner joins to get the latest non null value of a column, and thus we can thing in spark could also be difficult however, we will see otherwise.
One of the least known spark features is windowing. I have recently discovered how powerful and simple it is. Let's talk our way through it.
Window functions are extremely useful to carry out unique aggregations that can be defined by using a reference to the current data. In our case, we want to compare always with rows of the same identifier, and aggregate them to obtain the newest information for each column.
import org.apache.spark.sql.expressions.Window
val w = Window.partitionBy('id).orderBy('time).
rangeBetween(Window.unboundedPreceding, Window.unboundedFollowing)
WARNING: Beware data skew
We have discovered here the two most important columns to do the magic:
- One or more keys to partition by
- A versioning column: this can be a timestamp or an always increasing number. Will allow us to select the newest data
Once we have the windowing function, we will need to do two different types of operations:
- For each column not being part of the primary key or the versioning column, get the last (newest) record with a not null value. For example:
df.withColumn("val1",last('val1, ignoreNulls = true).over(w)).
withColumn("val2",last('val2,true).over(w))
2. Filter old rows to keep only one value of the PK using an auxiliary column. It is important to apply the filter last or it won't work.
3. Drop the auxiliary versioning column
updatedDf.withColumn("time_u",last("time").over(w)).
filter("time_u==time").drop('time_u)
In our toy example, the result is what we wanted
| id | time | val1 | val2 |
|---|---|---|---|
| 1 | 2 | dataa | updateddata |
DISCLAIMER: The exact code showed is not tested with big volumes, so it might not be efficient. This is just to explain one useful feature of windowing functions. However, similar code for just one column and bigish volumes (1TB) seems to be twice as fast as a join approach.
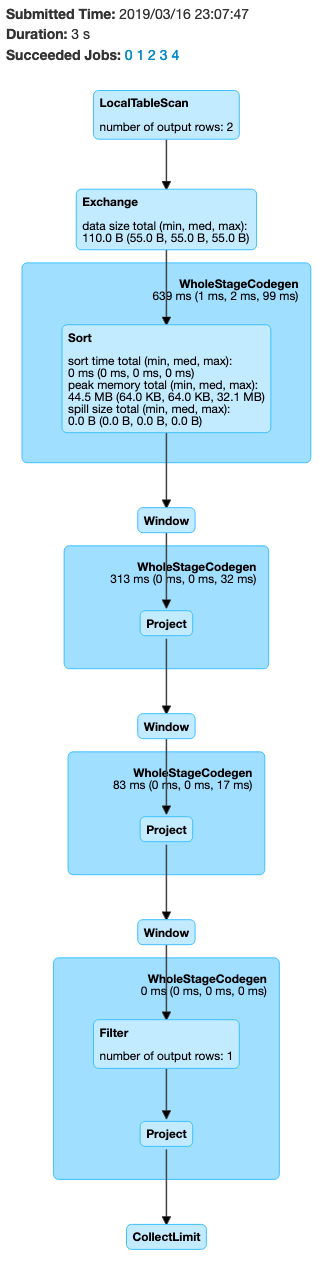
The generated dag looks promising: we just have one shuffle part and despite having multiple jobs, we avoid ugly looking joins.
One step beyond
Once the basis have been set, we can move-on to automate the generation of the code, so we do not have to be schema-tied. I'm going to build a simple function to generate the code needed once a dataframe, PKs and a versioning column are provided.
import org.apache.spark.sql.Dataset
def newestValues[T](df: Dataset[T], pks: Seq[String], versionCol: String) = {
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions.col
val w = Window.partitionBy(pks.map(col): _*).orderBy(versionCol).
rangeBetween(Window.unboundedPreceding, Window.unboundedFollowing)
val filterOutCols = versionCol +: pks
val otherCols = df.schema.map(_.name).filterNot(filterOutCols.contains)
otherCols.foldLeft(df.toDF){ (df, c) =>
df.withColumn(c,last(c, ignoreNulls = true).over(w))
}.withColumn(versionCol + "_aux",last(versionCol).over(w)).
filter(versionCol + "_aux == " + versionCol).drop(versionCol + "_aux")
}
Another thing we could do to try to improve efficency is to play with the ranges since we are not interested in extending the windows over an infinite range. Let's say we add another column to our data
| id | time | val1 | val2 |
|---|---|---|---|
| 1 | 1 | dataa | dataaOld |
| 1 | 3 | upd | |
| 1 | 2 | updateddata |
def newestValues2[T](df: Dataset[T], pks: Seq[String], versionCol: String) = {
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions.col
val w = Window.partitionBy(pks.map(col): _*).orderBy(versionCol).
rangeBetween(Window.unboundedPreceding, Window.currentRow)
val wVers = Window.partitionBy(pks.map(col): _*).orderBy(versionCol).
rangeBetween(Window.currentRow, Window.unboundedFollowing)
val filterOutCols = versionCol +: pks
val otherCols = df.schema.map(_.name).filterNot(filterOutCols.contains)
otherCols.foldLeft(df.toDF){ (df, c) =>
df.withColumn(c,last(c, ignoreNulls = true).over(w))
}.withColumn(versionCol + "_aux",last(versionCol).over(wVers)).
filter(versionCol + "_aux == " + versionCol).drop(versionCol + "_aux")
}
Testing the latest approach, we can see how it works if we print the dataframe before filtering.
| id | time | val1 | val2 | time_aux |
|---|---|---|---|---|
| 1 | 1 | dataa | dataaOld | 3 |
| 1 | 2 | dataa | updateddata | 3 |
| 1 | 3 | upd | updateddata | 3 |


![Leptos: rust full stack [Code + Slides + Video]](/content/images/size/w600/2025/12/leptos-talk.png)
