Set-up pyspark in Mac OS X and Visual Studio Code

After reading this, you will be able to execute python files and jupyter notebooks that execute Apache Spark code in your local environment. This tutorial applies to OS X and Linux systems. We assume you already have knowledge on python and a console environment.
1. Download Apache Spark
We will download the latest version currently available at the time of writing this: 3.0.1 from the official website.
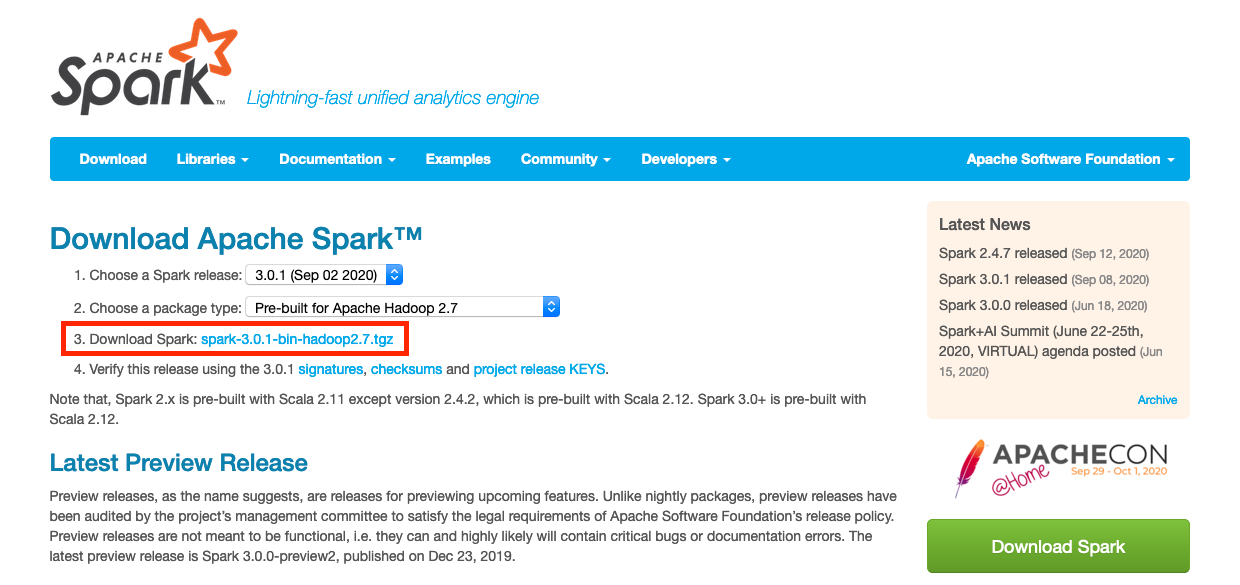
Download it and extract it in your computer. The path I'll be using for this tutorial is /Users/myuser/bigdata/spark This folder will contain all the files, like this
Now, I will edit the .bashrc file, located in the home of your user
$ nano ~/.bashrc
# Or, for savages
$ vi ~/.bashrc
Then we will update our environment variables so we can execute spark programs and our python environments will be able to locate the spark libraries.
export SPARK_HOME="/Users/myuser/bigdata/spark"
export PYTHONPATH="$PYTHONPATH:$SPARK_HOME/python:$SPARK_HOME/python/lib"
export PATH="$PATH:$SPARK_HOME/bin"
Save the file and load the changes executing $ source ~/.bashrc. If this worked, you will be able to open an spark shell.
$ spark-shell
20/12/08 12:03:29 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
20/12/08 12:03:37 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
Spark context Web UI available at http://fermi.home:4041
Spark context available as 'sc' (master = local[*], app id = local-1607425417256).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.1
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_101)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
We are now done installing Spark.
2. Install Visual Studio Code
One of the good things of this IDE is that allows us to run Jupyter notebooks within itself. Follow the Set-up instructions and then install python and the VSCode Python extension.
Then, open a new terminal and install the pyspark package via pip $ pip install pyspark. Note: depending on your installation, the command changes to pip3.
3. Run your pyspark code
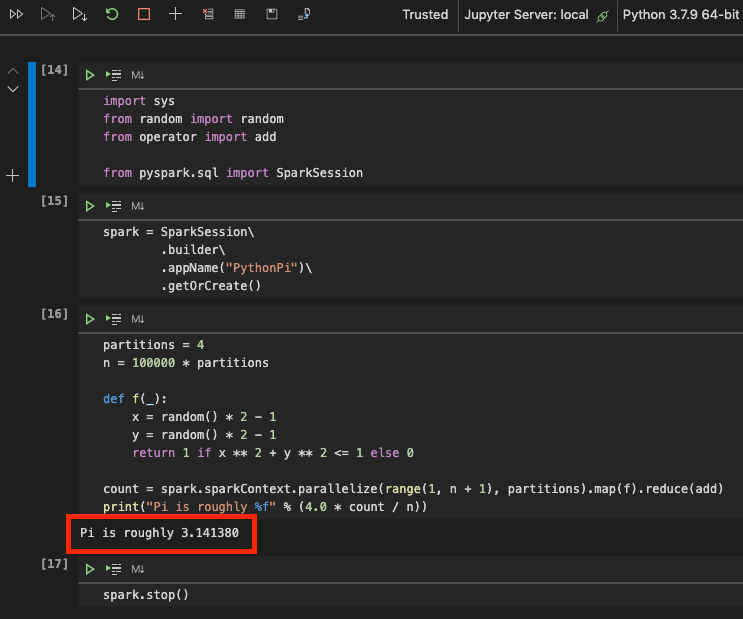
Create a new file or notebook in VS Code and you should be able to execute and get some results using the Pi example provided by the library itself.
Troubleshoot
If you are in a distribution that by default installs python3 (e.g. Ubuntu 20.04), pyspark will mostly fail with a message error like pysparkenv: 'python': No such file or directory.
The first option to fix it is to add to your .profile or .bashrc files the following content
export PATH=$PATH:/home/marti/bin
export PYTHONPATH=/usr/lib/python3
export PYSPARK_PYTHON=python3
export SPARK_HOME=/your/spark/installation/location/here/spark
export PATH=$PATH:/$SPARK_HOME/bin
export PYTHONPATH=$PYTHONPATH:$SPARK_HOME/python:$SPARK_HOME/python/lib
Remember to always reload the configuration via source .bashrc
In this case, the solution worked if I executed pyspark from the command line but not from VSCode's notebook. Since I am using a distribution based on debian, installing tehe following package fixed it:
sudo apt-get install python-is-python3


![Leptos: rust full stack [Code + Slides + Video]](/content/images/size/w600/2025/12/leptos-talk.png)
