SQL + DataOps = SQLMesh?
DBT is valuable but lacking. SQLMesh promises enhancements like unit tests, environments, airflow support, change plans, and CI/CD automation, providing a better development experience. Let's see its features.


I've set-up and used DBT (Data Build Tool) in a couple scale-ups and every time I had the feeling that it's a great improvement over what we had, but there are several pieces missing, something is left too much to the interpretation and might cause more chaos than it should be.
As a first example, what they define as tests it's not what software engineers think as unit tests. A pattern where you define some input apply a function and then expect some output. A small piece of code where you are testing the logic of an individual transformation. In DBT, tests are more akin to data quality tests (so Integration/e2e) since you are testing logic AND data. So how do I test the result of adding two columns if I don't know what data do I have?
Tied to this limitation, and an issue with data applications in general, is how are your life cycles. On one hand you have the typical software lifecycle but on the other you have the data lifecycle. It's not a good practice (nor economical) to just use production data in DEV and QA environments but at the same time it's needed if you have to validate business transformations like monthly revenue. What do you do?
flowchart
client[[User/APP]]
code[[Transformations/SQL]]
ncode[[New Transformations/SQL]]
subgraph "PROD"
client --> d_p[(Raw data)]
d_p --- code
d_p .-> a_p[(Report)]
code --> a_p
end
subgraph "DEV"
d_q[(Raw dev data)]
d_q --- ncode
d_q .-> a_d[(Report)]
ncode --> a_d
end
PROD ~~~ DEV
d_p .->|copy subset\nevery time neededd| d_q
classDef red stroke:#f00
classDef green stroke:#0f0
classDef blue stroke:#00f
class ncode blue;
class code, green;
We can have a process to periodically move all the data to dev environment. This will have some challenges if data is big and we will never have the updated numbers, so it will be hard to test the fix for some bugs.
flowchart
client[[User/APP]]
code[[Transformations/SQL]]
ncode[[New Transformations/SQL]]
subgraph "PROD"
client --> d_p[(Raw data)]
d_p --- code
d_p .-> a_p[(Report)]
code --> a_p
end
subgraph "DEV"
d_p --- ncode
d_p .->|read always\nfrom prod| a_d[(Report)]
ncode --> a_d
end
PROD ~~~ DEV
classDef red stroke:#f00
classDef green stroke:#0f0
classDef blue stroke:#00f
class ncode blue;
class code, green;
On the other hand we could read directly from production environment. While some databases support some sort of zero-copy feature where the impact of this should be low, in most cases we are going to overload productive systems which we want to avoid.
flowchart
client[[User/APP]]
code[[Transformations/SQL]]
ncode[[New Transformations/SQL]]
subgraph "PROD"
client --> d_p[(Raw data)]
d_p --- code
d_p .-> a_p[(Report)]
code --> a_p
end
subgraph "DEV"
client --> d_q[(Raw dev data)]
d_q --- ncode
d_q .-> a_d[(Report)]
ncode --> a_d
end
PROD ~~~ DEV
classDef red stroke:#f00
classDef green stroke:#0f0
classDef blue stroke:#00f
class ncode blue;
class code, green;
Finally, we could write productive data to our DEV (there are ways of not adding additional load to the source systems) and work with productive data with low latency. Here we also face some issues related to bad practices, but in the end it's really hard to overcome if we need to mirror the results we show our internal users in production.
We see that it's not easy to implement a lifecycle for data transformations, and the fact that multiple analysts are going to be working at the same time even complicates more the things.
Long story short, I'm looking for an opinionated tool that will help me with all of the following:
mindmap root((perfect
tool)) Tests Type Unit-like Quality Continuously run
in production Library ready to use Custom SQL Report Deployment Opinionated
lifecycle Integrates with git
PR, comments... Downstream
changes CICD pipelines Tests before
merging SQL linting Ops Schema
evolution Integrates with
airflow Supports multiple
databases Data
update modes Full Incremental Delta Hands off Development IDE Can execute Models Shows
lineage Can execute SQL Edit
documentation Lineage Column level Macros
And a few extras:
- Thriving community
- API for everything
- Iceberg support
- LLM to write sql (nice to have)
So I heard about SQL mesh and it ticked a lot of items in my list. Let's check it out a bit.
Integrations
First of all, does it support most of execution engines? Yes. Besides the typical cloud ones (Spark, Databriks, BigQuery, Snowflake, redshift) it also suports traditional RDBMS, trino, and DuckDB/MotherDuck for those situations where you want an analytical engine but don't need distributed computation. Nice.
It also has automatic support for airflow, unlike what was happening with DBT, where every company/team had to create custom airflow code to execute dbt and all of the different steps.
from sqlmesh.schedulers.airflow.integration import SQLMeshAirflow
sqlmesh_airflow = SQLMeshAirflow("spark", default_catalog="spark_catalog")
for dag in sqlmesh_airflow.dags:
globals()[dag.dag_id] = dagLifecycle
It's great that one of the sections it Github Actions CI/CD bot and a quick reading has my heart racing. There are automation for
- Unit test on PR
- PR environments
- Back-fill data for changed models
- Deploy changes to production and merge PRs
This seems dark magic, how is this achievable in a general way?
Well, with some caveats and limitations, and a decision to be taken. It ties software lifecycle to data lifecycle. It gives us two opinionated options to choose from, and I start liking their approach.
- Desync deployment is more or less what we might be used to. You merge the code and eventually a cron job deploys the changes to production. This however introduces lags and will batch multiple changes together.
- Sync deployment: SQLMesh takes control of the code merges, and it executes code merge when the changes are deployed to production. It's interesting and might solve several problems in real world scenarios. Instead of copying the data across the multiple environments, they have a single schema with all the data versions, and views pointing to the correct version of the model. This way, releasing a model to production can be as fast as changing a view.
Development
IDE
I've seen this part being a challenge in multiple groups of people. From data analysts more used to SQL interfaces to students with a bit of programming knowledge but more used to notebooks than IntellIJ and VSCode. So a good tool requires a good development environment.
In this case, besides supporting CLI and python SDK (for notebooks and automation), they provide a web IDE
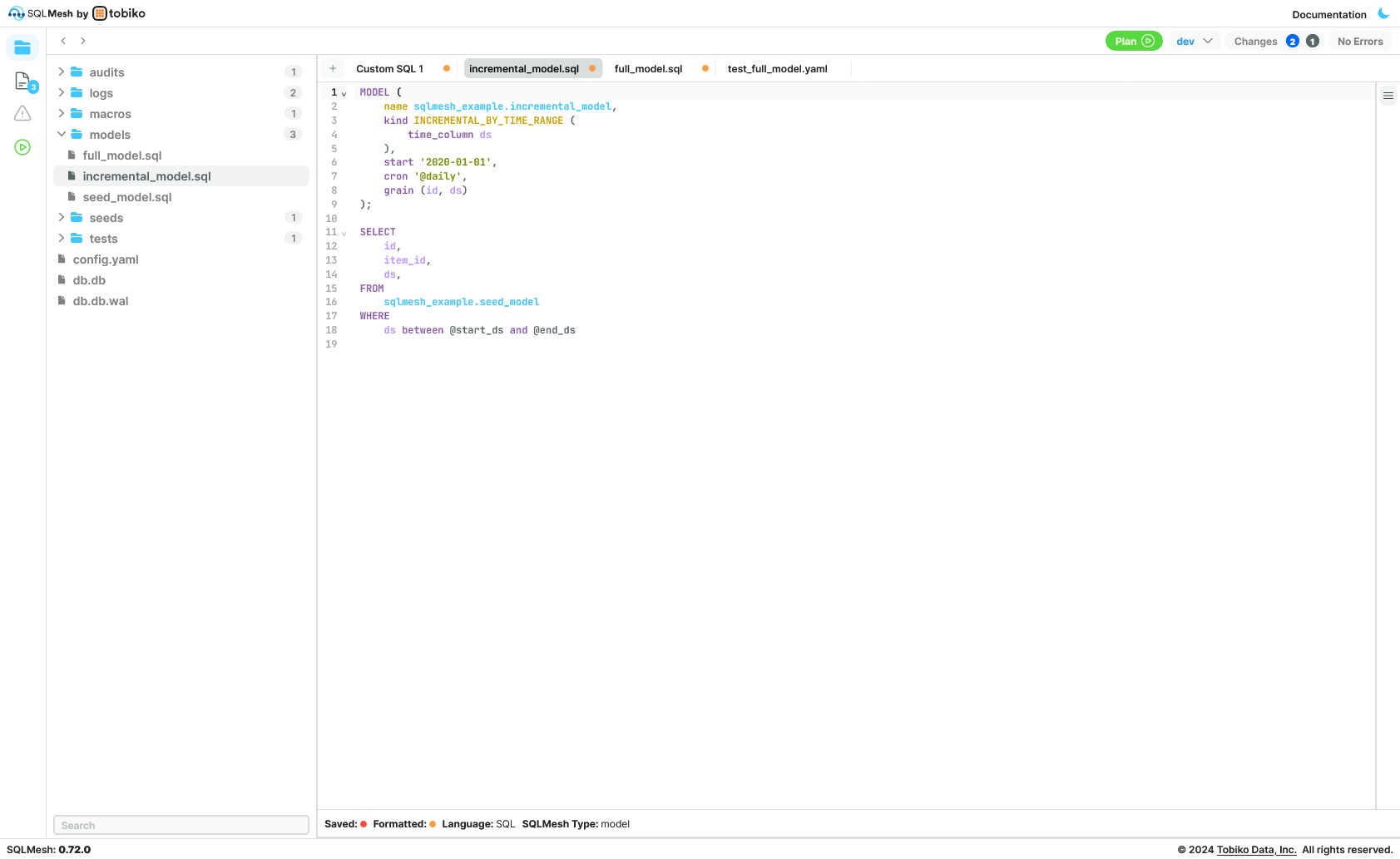
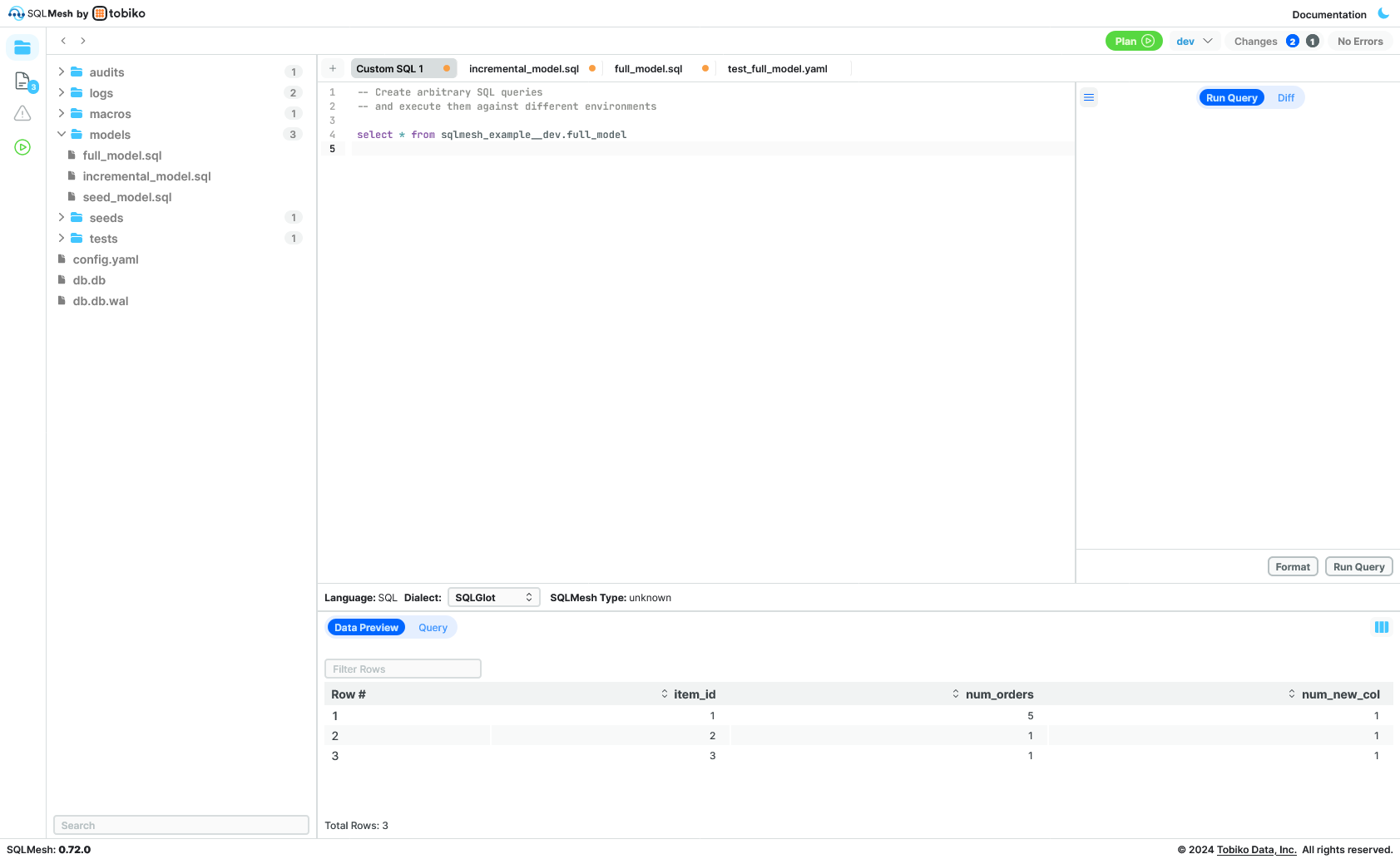
It also shows lineage and allows you to execute on dev and other environments. Overall, like DBT cloud but without paying 100€/developer and way better than VSCode + DBT plugin.
Tests
Finally we can specify unit tests and data quality tests (called audits).
It provides (unit) tests which are simply defined as input and output
test_example_full_model:
model: sqlmesh_example.full_model
inputs:
sqlmesh_example.incremental_model:
rows:
- id: 1
item_id: 1
ds: '2020-01-01'
- id: 2
item_id: 1
ds: '2020-01-02'
- id: 3
item_id: 2
ds: '2020-01-03'
outputs:
query:
rows:
- item_id: 1
num_orders: 2
- item_id: 2
num_orders: 1And audits (data quality) which is actually a bunch of SQL files that work as macros. You define them inside the audit folder and then in the model definition you link it.
The generic audits already implemented have a good coverage but it would be good if it can be implemented at the level of other packages like great expectations.
Use it now!
The best way to try this tool is that you can use your existing DBT project! With one command and probably a couple changes, you'll have enough time to explore and share it with your colleagues.
Recap
This was just an overview, but it's a promising tool with several quality of life features. It has a lot of the same features and development experience as DBT but with several extras like unit tests, environments, airflow support, change plans and CI/CD automation.
In my opinion is well worth it doing a PoC reusing your existing DBT project.
For sure I'll test it next time I have to work in a data warehouse.


![Leptos: rust full stack [Code + Slides + Video]](/content/images/size/w600/2025/12/leptos-talk.png)
