Spark SQL and Type-safe (1): Quill


Recently I have been discussing with some colleagues the advantages of type-safe languages, the main reason I ditched python for Scala. Scala provides, for me the best of both worlds: the compiler is smart enough to determine variable types, and in the most cases it even can infer return types of functions and methods.
However, it enforces to explicitly determine the types in parameters, public methods and recursive functions. This fact allows me to be able to determine what type of variable/return I will have at a glance, thing that does not happen in Python or R. In those languages, despite using frameworks very well-written (Airflow is an example), I never know what type I have to pass nor what I am reviving. In those cases, the solution is to look at the code itself (again, Airflow code is, imo, well written and the method parameters are well explained and documented). But because I am human, mistakes happen, and it is not nice to encounter them at run/test time, since sometimes errors are not clear enough, for example, when using sqlAlchemy.
This made me think about Spark's involution in Type-safe. With RDD, you were driven to use case classes, that granted you the ability to select a column just typing rdd.map(_.name) for example. Using the new structured API, it's simple: df.select("name"). This expression is sql-like and can be understood by non spark-initiated coders and analysts. However, it introduces a very significant entry point for human failure: column names are just a string. And it has an awful consequence: you encounter them at run time. For me, someone who is prone to commit erratas, this is a the opposite of a killer feature.
A long time ago, I assisted to a Spark Meetup Barcelona talk where the speaker talked about type-safe and Spark SQL. I can only remember parts of what he talked about, but he rambled about cats library and compiling time being too long. When this meetup came to my mind earlier, was the GO signal I needed: there is a future with spark and type-safe. Let's duck a solution for our problem!
Quill: the sqlAlchemy of type-safe?
Quill was the first option I saw. Written as a personal open-source code by Flavio Brasil, a software engineer at Twitter. Using Flavio's definition: Quill is able to transform collection-like code into SQL queries without any special mapping, using regular case classes and Scala functions. Those classes are parsed and transformed into an AST that is later converted to SQL statements.
This is elegant in my opinion: you leverage spark's Dataset API and its heavy optimizations executing the resulting SQL however, you write your queries using RDD-like code, but with all spark's SQL optimizations!
Furthermore, this library is not limited to Spark: it can be used to interact with a broad range of databases and its different dialects. It might well be in its way to become Scala version of python's sqlAlchemy: one framework to rule all databases.
- MySQL
- Postgres
- Sqlite
- SQLServer
- Cassandra
The premise is simple: use case classes to describe your data pass Dataset[T]s to the library. First of all, we will need to create our classes and import some implicits that must be in the scope of the library's methods.
case class Person(id: BigInt, user_name: String, first_name: String,
last_name: String, password: String, email: String, gender: String,
city: String, street: String, street_number: Option[Int], first_ip: String)
case class Login(person_id: BigInt, ip: String, timestamp: Timestamp)
val spark = SparkSession...getOrCreate()
implicit lazy val sqlContext: SQLContext = spark.sqlContext
import spark.implicits._
val persons = spark.read(...).as[Person]
val logins = spark.read.(...).as[Login]
By the way, I have discovered some of the new features of the latest version of Intellij's Scala plugin and I love them!

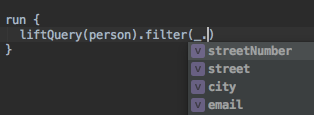
In the same scope we have both implicits, we can start building our queries.
val filtered: Dataset[Person] = run {
liftQuery(persons).filter(_.street_number.nonEmpty)
}
// SELECT gender, count(*) FROM filtered GROUP BY gender
val simple_group = run {
liftQuery(filtered).groupBy(p => p.gender)
.map{
case (gender, person) => (gender, person.size)
}
}
simple_group.show()
// SELECT last_name, first_name, gender FROM filtered ORDER BY last_name, first_name
val sorted = run {
liftQuery(filtered).sortBy{ p => (p.last_name, p.first_name)}(Ord.asc)
.map(p => (p.last_name, p.first_name, p.gender))
}
sorted.show()
However, as you can see, this solution has a very big drawback: its collection like syntax narrows the target users to those loving Scala's functional approach for collections. New users coming from other languages like Java and Python or R, won't find this approach attractive.
Furthermore, it allows us to write multiple queries that do the same, potentially ending in having to write more. E.g. the following query is the same as the last one, but depending on the order we put the operations, we will have to choose between readability and having a concise code.
val sorted2 = run {
liftQuery(filtered).map(p => (p.last_name, p.first_name, p.gender))
.sortBy{ case (last_name, first_name, gender) => (last_name, first_name)}(Ord.asc)
//.sortBy(r => (r._1, r._2))(Ord.asc)
}
This issue would be anecdotical if it wasn't by some catastrophical problems with its parser and SQL compiler. On one hand, I have found problems when trying to concatenate some operation to a distinct. Despite doing a filter, the compiler stil thought that I had a dataset of Login instead of being [String, BigInt]. The workaround was to split the operations in two variables.
// SELECT ip FROM (SELECT distinct ip, person_id FROM Logins) GROUP BY ip HAVING count(person_id) > 1
val distinctIpUser =run {
liftQuery(logins).map(l => (l.ip, l.person_id))
.distinct
}
val ipMultipleUsersLogin = run {
//liftQuery(logins).map(l => (l.ip, l.person_id))
// .distinct // DOES NOT WORK
liftQuery(distinctIpUser)
.groupBy{ case (ip, _) => ip }
.map{ case (ip, persons_id) => (ip, persons_id.size) }
.filter(_._2 > 1)
.map(_._1)
}
On the other hand, joins are pretty intuitive
val potentialMultiaccounts = run {
liftQuery(usersLoginIp).join(liftQuery(ipMultipleUsersLogin))
.on{ case ((ip, _), ip2) => ip == ip2}
.map{ case (ipUser, _) => ipUser }
.sortBy(_._1)
}
Attention: You can face some nasty errors when grouping by two fields. This is caused due to an incompatibility of spark's SQL language and the one generated by Quill. More info in this bug report.
All in all, Quill's spark integration is not quite as polished as one would desire in order to use it from time to time. While useful when writing simple queries, it becomes unbearable when doing something more "complex" involving distincts, selects or group bys of multiple columns.
You can see the full code used for this series of posts in my github repo.
Spark SQL and Type-safe (2): Frameless
We will cover frameless, another library powered by shapeless and cats that can help us work safer with spark. (coming soon-ish)
![Leptos: rust full stack [Code + Slides + Video]](/content/images/size/w600/2025/12/leptos-talk.png)