Spark and HugginFace: Named Entity Recognition for aircraft ownership
How to use one of the best AI/ML libraries (hugginface) with Spark? Let's try it


The problem and the data
We want to know which aircraft is owned by an individual and which one is owned by a company. This way, we can later analyze the overall impact of private jets versus charter ones.
We can obtain the ownership of an airplane in several ways (it's public data), but in this exercise we will limit ourselves to a single source: the aircraft database from ADS-B Exchange.


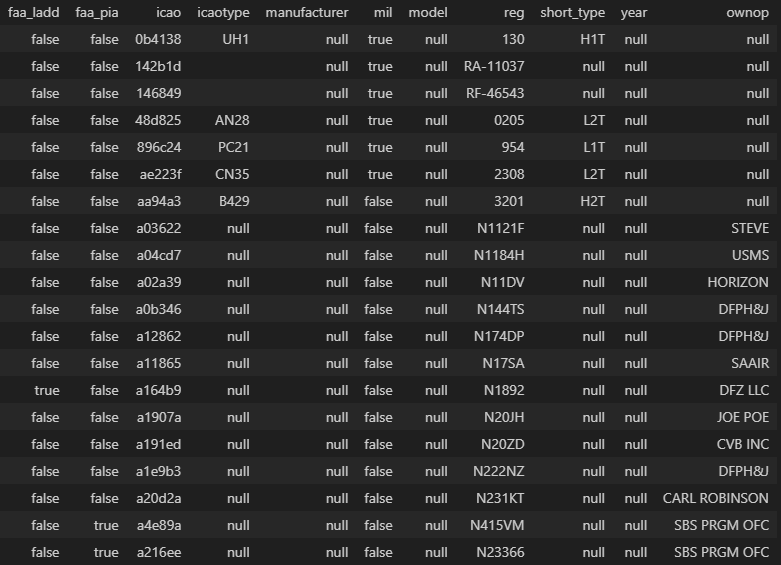
There are multiple columns related to plate numbers, type of plane and some US aviation flags but we'll just use ownop which is the owner of the aircraft.
State-of the art "AI" model
The best thing about Huggin Face is how easy it is to use pre-trained models. It's just browsing through their catalog, testing a couple of them and selecting the one we prefer with a couple of lines of code. And that is it!
In this case, I've selected the bert-base-NER model, wich is a fine-tuned BERT model for Named Entity Recognition. There is a more powerful version but for now it will be good.
There are a couple of limitations of this algorithm:
- It "occassionally tags subword tokens as entities".
- It gives better results with sentences. We just have names.
Overcoming those limitations will require some pre and post processing but it's outside the scope of this post.
How can we use it? Well, that is not really difficult if we use python. As their documentation says, after installing transformers and pytorch ( pip install torch torchvision torchaudio in our case), we can execute the following:
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-base-NER")
model = AutoModelForTokenClassification.from_pretrained("dslim/bert-base-NER")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "My name is Wolfgang and I live in Berlin"
ner_results = nlp(example)
print(ner_results)We'll obtain something like this:
[
{'entity_group': 'PER', 'score': 0.9990139, 'word': 'Wolfgang', 'start': 11, 'end': 19},
{'entity_group': 'LOC', 'score': 0.999645, 'word': 'Berlin', 'start': 34, 'end': 40}
]But as we saw, our data will be in the form of Bill Gates ,Elon Muks or SBS PRGM OFC. So we are assuming that we only care about one entity group and we'll eventually need to correct.
Small optimizations
There will be two small optimizations that will depend on your hardware and the algorithm used:
ner = pipeline("ner", ..., device=device)with0for GPU or-1for only CPUnlp= ner(owners_list, batch_size=256)changing the batch size to find the best performance
This batch_size refers to the data elements that will be passed to the GPU at a time, but the performance will depend on the model you are using. For our case, 256 is just right.
- 37 min with
batch_size=1- 9.2 min with
256- 13 min with
512The spark part
| Software | Version |
|---|---|
| Pyspark | 3.3.0 |
| transformers | 4.29.1 |
| torch | 2.0.1 |
Loading the data
I'm going to use pyspark (since we already use python) and execute spark in standalone mode. Make sure to give enough memory to the driver since it will be required, as we will see later.
import time
import psutil
from utils import *
from pyspark.sql import SparkSession, DataFrame
from pyspark.sql.functions import *
memory_to_use = int(psutil.virtual_memory().total/1024/1024//1024-2)
spark = SparkSession.builder \
.master("local[5]") \
.appName("Spark with Transformers") \
.config("spark.sql.repl.eagerEval.enabled", True)\
.config("spark.sql.repl.eagerEval.truncate", 100)\
.config("spark.driver.memory",f"{memory_to_use}g") \
.config("spark.driver.maxResultSize", 1024*1024*1042*4)\
.config('spark.sql.shuffle.partitions',300)\
.config('spark.worker.cleanup.enabled', 'True')\
.config("spark.sql.session.timeZone", "UTC")\
.getOrCreate()
spark# Aircrafts list
aircrafts = spark.read.json(f"data/basic-aircraft-db.json.gz").drop("_corrupt_record").\
where("icao is not null").\
withColumn("ownop_good", when(col("ownop") == "", None).otherwise(col("ownop"))).\
drop("ownop").withColumnRenamed("ownop_good", "ownop")
aircrafts.persist()
aircraftsUser defined functions
To use our model, we'll need to use a User Defined Function, a nive (and not really efficient) way of applying custom python transformations to our data.
Why is that not efficient? Well, in this case we need to think about what happens under the hood. Our data is inside the Java Virtual Machine, in an efficient memory format. Then, we need to move it from the efficient format to Java types and then move it to the python threads and format. We can then apply python code on this data and spark will convert it back again.
Taht might be a bit complex, but long story short: we have a lot of overhead of data transformations. And this happens for each cell value if we use udf function, so it will get called for at least each row of our dataset.
This is not efficient since we need to download the model everytime. Since our pipeline might need to run in a distributed cluster, a shared python variable will not work. That's why we need to turn into pandas_udf function that will give us a pandas series with more than one value (actually, one series per data partition it seems).
But if we have a huge dataset it will be slow (see later), so we'll use another optimization available to us.
Iterated pandas_udf
If we use the normal version of pandas udf, this takes a lot of time since it transforms all the data inside a partition to a pandas series. On my computer with a beefy GPU, it takes more or less 2 minutes for 25k rows. Keep in mind that we have 400k! When I tried with 400k, the spark process froze in a way I could not kill it. So I don't recommend you trying it.
@pandas_udf('string')
def detect_entities_inefficient_udf(owners: pd.Series) -> pd.Series:
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
import torch
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-base-NER")
model = AutoModelForTokenClassification.from_pretrained("dslim/bert-base-NER")
device = 0 if torch.cuda.is_available() else -1
ner_pipeline = pipeline("ner", model=model, tokenizer=tokenizer, aggregation_strategy="max", device=device)
entities = [(result[:1] or [{}])[0].get("entity_group") for result in ner_pipeline(owners.to_list(), batch_size=256)]
return pd.Series(entities)
ac_inefficient = aircrafts.limit(25000).\
withColumn("ownop_type", detect_entities_inefficient_udf(when(aircrafts.ownop.isNull(), "nothing").otherwise(aircrafts.ownop)))
ac_inefficient.write.parquet("data/ac_enriched_inefficient")So we'll need to request an iterator Iterator[pd.Series] It will return us series of 10k rows at each time wich is way more efficient.
from pyspark.sql.functions import pandas_udf
import pandas as pd
from typing import Iterator
@pandas_udf('string')
def detect_entities_udf(owners_iter: Iterator[pd.Series]) -> Iterator[pd.Series]:
"""This should happen per partition in the executor nodes. So since models are not shared. initialize everything here"""
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
import torch
import time
device = 0 if torch.cuda.is_available() else -1
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-base-NER")
model = AutoModelForTokenClassification.from_pretrained("dslim/bert-base-NER")
ner = pipeline("ner", model=model, tokenizer=tokenizer, aggregation_strategy="max", device=device)
for owners in owners_iter:
pipe = ner(owners.to_list(), batch_size=256)
entities = [(result[:1] or [{}])[0].get("entity_group") for result in pipe]
yield pd.Series(entities)Now we just need to execute it though being intelligent with repartitioning. More partitions means more parallelization, though your GPU might act as a bottleneck, so a bit of testing is needed.
In any case something like this (~100k rows) took 26 seconds.
ac_efficient = aircrafts.limit(109000).repartition(6).\
withColumn("ownop_type", detect_entities_udf(when(aircrafts.ownop.isNull(), "nothing").otherwise(aircrafts.ownop)))
ac_efficient.write.parquet("data/ac_enriched_efficient2")Summary
- Use
pandas_udfwithIterator[pd.Series]datatypes - Load the model inside the
pandas_udf - Explore optimizations around HugginFace's
batch_sizeand dataFrame partitions - Use GPU machines (yeah, that will be faster)
- You'll always need a check on the results. They will not be 100% correct
Another option
Use SparkNLP. It's a bit more complex since you need to convert the pytorch model to tensorflow.
 Juan Martinez
Juan Martinez
Resources


.png)


![Leptos: rust full stack [Code + Slides + Video]](/content/images/size/w600/2025/12/leptos-talk.png)
