What is required to build a distributed system?


This entry contains some scattered thoughts that I don't want to loose, so I leave it here in case they are useful too.
Modeling your system
In distributed systems, the devil is everywhere so it's better if we start thinking about.
Sources of pitfalls:
- Time
- Latency
- Node clocks drift, skip...
- I/O
- Disk
- Memory (e.g. memory hammering)
- Caches
- Network
- Concurrency
- Race conditions
Testing the designs https://www.learntla.com/
From The video: "How to write your own Deterministic Simulator", they said that while RAFT algorithm is formally proved (and it's well understood by everyone), implementations tend to be a mess and have issues with specific hardware, software versions, etc. (minute 17:30). Those are implementation problems that do not make it into the model. And most implementations can lose data and have split brain.
Just testing your model does not mean that is going to work. You might have built an incomplete model for your proof. For example, what if you have network latency? Or node clocks drift?
You can have semantic gaps in your model causing all your implementations to be broken.
Chaos monkey meets local testing: DST
Deterministic Simulation Testing: you mock away all sources of uncertainties: e.g. all I/O related interfaces, clocks and physical distribution. And while it can be introduced later, doing it in the beginning will help you reason about failure surfaces of your DB/application.
It's like doing end to end testing in your local. To have a higher degree of certainty. How? Owning the event loop and all the interfaces: you can control what executes when, and even simulate time passing faster to ensure your hourly API request throttling is correct.
With Fault Injection, we can test the guarantees the software gives to the user. We can introduce Fault Models: Network, Storage (disks fail), Processes (crash), Clock... And some projects can do even CPU and Memory faults, but it's more complicated going into Byzantine surfaces (malicious actors trying to break your system).
And why deterministic? Well, if you ever had a pesky bug that does not always happen, you'll easily understand the reason: if a test fail in the CI pipeline, you can reproduce it exactly every time, so it's way faster to detect where the issue is.
However, you must build your application to be deterministic. Some data structures are not,


This is real simulation on real hardware. But it's not deterministic
Jepsen aims to improve the safety of distributed databases, queues, consensus systems, etc.
Thinking in performance
I come from the data world were we mostly use libraries that already interact with network, disks, RAM, CPU cache so I've never had to think much about it: the bottlenecks were usually in other parts. But if you want to write a low level system

And I'm reading this as part of a bookclub. It's a bit dated (2007) but still relevant: What Every Programmer Should Know About Memory - Ulrich Drepper
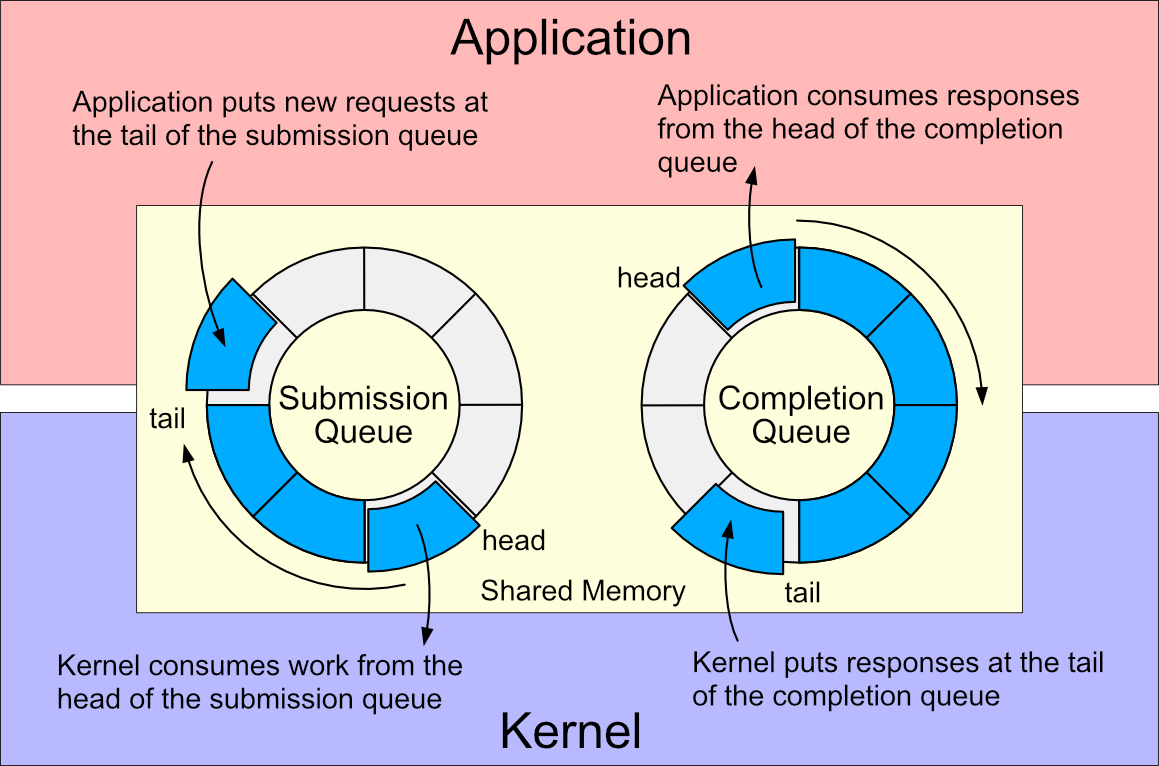
- IO_uring
- Async I/O in linux with ring buffers: queue multiple work requests and make a single syscall to submit it.
- Data oriented programming (optimize you CPU cache)
- Columnar data
- Compression, fast retrievals...
- Indexes, data structures and keeping them in sync
- There are some that are write optimized and others that are read
- LSMTrees, Bf-tree...
- Zero-copy deserialization
- Thread-per-core architecture
PoC of what optimizing can give you: with optimizing writes to storage device block sizes (avoiding page caches), hashing data structures and io_uring instead of traditional I/O made this library fly and saturate SSD interfaces. Resulting in several orders of magnitude faster than the compared libraries. (note: also because other libraries implement more features)
An example of all of this is Apache Iggy, a message-streaming platform for extremely low latency (1ms)

Distributed algorithms
Modern file systems typically use a variant of WAL for at least file system metadata; this is called journaling.
Usually each node has its own copy of the log, but with a level of coordination between nodes where the leader will not advance unless it has received an ACK from a majority. A couple examples are Multi-paxos and RAFT.
- Consensus
- The network is never reliable, so you might have disagreements between nodes
- From "who is the leader" to "is this piece of data replicated enough times"
- Time
- Hardware clocks are unreliable, so databases implement their own notion of time via logical clocks. E.g. Lamport, vector clock...
- Failure modes and tolerance
- Detection and mitigation
- Spatial failures (app-level or platform-level)
- Temporal (transient, intermitteny or permanent)
Resources

Turso have used deterministic simulation testing for their SQLite rewrite.

![Leptos: rust full stack [Code + Slides + Video]](/content/images/size/w600/2025/12/leptos-talk.png)

